모두를 위한 딥러닝 2 - Lab9-3:Dropout
모두를 위한 딥러닝 Lab9-3: Dropout 강의를 본 후 공부를 목적으로 작성한 게시물입니다.
Dropout
lab7-1에서 알아본 것처럼 학습을 하다보면 train set에 너무 과적합(overfitting)되는 경우가 발생한다.
이때 언급한 과적합을 덜어주기 위한 방법에는 다음과 같은 것들이 있었다.
- Early Stoping: valid set의 loss가 줄어들지 않을 때 학습을 중지한다.
- Reducing Network Size
- Weight Decay: weight가 너무 커지지 않도록 wight가 커질수록 함께 커지는 penalty를 부여한다.
- Dropout: node의 일부를 꺼서 학습하는 node를 줄인다.
- Batch Normalization: 학습 중에 배치 단위로 정규화 하는 것
오늘은 이 중에서 dropout에 대해 알아보려 한다.
dropout은 일정 확률에 따라 레이어의 node를 끄면서 학습을 진행하는 것을 말한다. 즉, 레이어의 일부 node를 학습에 사용하지 않는 것이다.
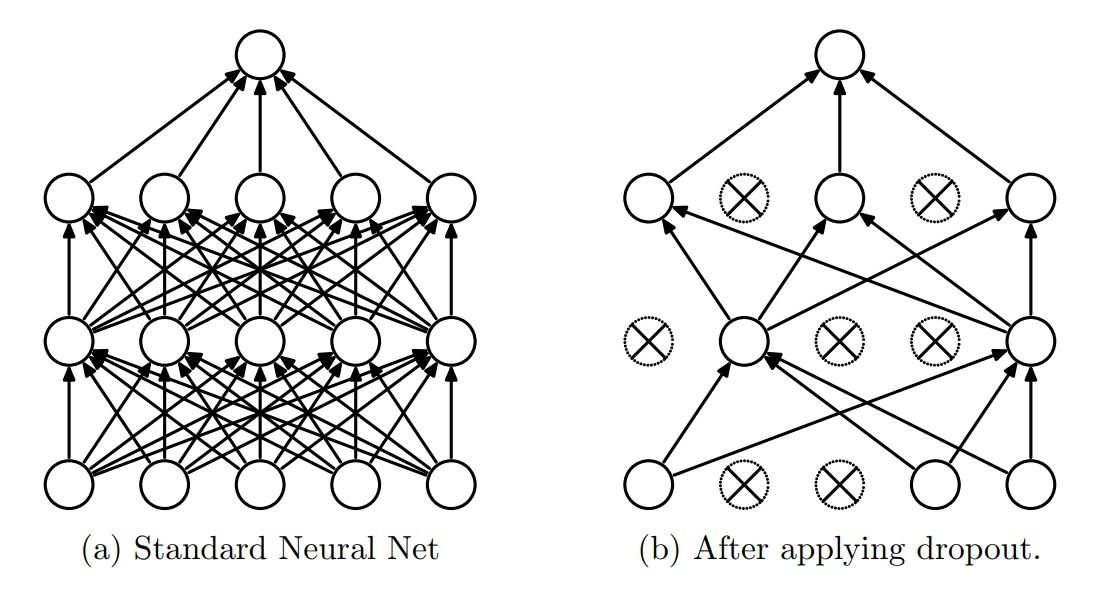
위 그림처럼 각 노드들은 일정한 확률로 비활성화 한다. 이런 식으로 학습을 하게 되면 과하게 학습되는 것을 막아 과적합 모델이 만들어지는 것을 막을 수 있을 뿐만 아니라. 각 시행마다 확률적으로 꺼지고 켜지는 node가 달라지기 때문에 다양한 네트워크로 학습하여 앙상블한 효과도 얻을 수 있어 성능의 향상으로도 이루어질 수 있다고 한다.
Train with MNIST
학습하는 코드는 모델의 구성할 때 dropout이 추가된 것 말고는 큰 변화가 없지만 주의해야 할 점이 있다. 먼저 코드를 보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# nn layers
linear1 = torch.nn.Linear(784, 512, bias=True)
linear2 = torch.nn.Linear(512, 512, bias=True)
linear3 = torch.nn.Linear(512, 512, bias=True)
linear4 = torch.nn.Linear(512, 512, bias=True)
linear5 = torch.nn.Linear(512, 10, bias=True)
relu = torch.nn.ReLU()
dropout = torch.nn.Dropout(p=drop_prob)
# xavier initialization
torch.nn.init.xavier_uniform_(linear1.weight)
torch.nn.init.xavier_uniform_(linear2.weight)
torch.nn.init.xavier_uniform_(linear3.weight)
torch.nn.init.xavier_uniform_(linear4.weight)
torch.nn.init.xavier_uniform_(linear5.weight)
# model
model = torch.nn.Sequential(linear1, relu, dropout,
linear2, relu, dropout,
linear3, relu, dropout,
linear4, relu, dropout,
linear5).to(device)
여기까지는 Sequential통해 모델을 구성할 때 dropout을 추가해 준 것 말고는 다른 것이 없지만 아래를 보면 학습하기 전에 model.train()이라는 새로운 코드가 추가된 것을 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
total_batch = len(data_loader)
model.train() # set the model to train mode (dropout=True)
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
# reshape input image into [batch_size by 784]
# label is not one-hot encoded
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning finished')
'''output
Epoch: 0001 cost = 0.308392197
Epoch: 0002 cost = 0.142623395
Epoch: 0003 cost = 0.113427199
Epoch: 0004 cost = 0.093490042
Epoch: 0005 cost = 0.083772294
Epoch: 0006 cost = 0.077040948
Epoch: 0007 cost = 0.067025252
Epoch: 0008 cost = 0.063156039
Epoch: 0009 cost = 0.058766391
Epoch: 0010 cost = 0.055902217
Epoch: 0011 cost = 0.052059878
Epoch: 0012 cost = 0.048243146
Epoch: 0013 cost = 0.047231019
Epoch: 0014 cost = 0.045120358
Epoch: 0015 cost = 0.040942233
Learning finished
'''
이건 model을 train 용으로 사용할 것인지, eval 용으로 사용할 것인지에 따라 mode를 변경시켜주는 코드이다. (이후에 나올 batch normalization 등에서도 사용)
이렇게 모드를 나눠 주는 이유는 학습할 때와 달리 검증할 때는 dropout을 사용하지 않고 모든 node를 사용해서 예측을 진행하기 때문이다.
그러므로 검증할 때는 다음과 같이 코드를 작성해야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# Test model and check accuracy
with torch.no_grad():
model.eval() # set the model to evaluation mode (dropout=False)
# Test the model using test sets
X_test = mnist_test.test_data.view(-1, 28 * 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
# Get one and predict
r = random.randint(0, len(mnist_test) - 1)
X_single_data = mnist_test.test_data[r:r + 1].view(-1, 28 * 28).float().to(device)
Y_single_data = mnist_test.test_labels[r:r + 1].to(device)
print('Label: ', Y_single_data.item())
single_prediction = model(X_single_data)
print('Prediction: ', torch.argmax(single_prediction, 1).item())
'''output
Accuracy: 0.9820999503135681
Label: 8
Prediction: 8
'''
다른 부분은 모두 동일하게 작성하고 model.eval()만 추가하여 model을 검증하기 위한 mode로 바꿔주는 것을 볼 수 있다.