모두를 위한 딥러닝 2 - Lab9-2:Weight Initialization
모두를 위한 딥러닝 Lab9-2:Weight Initialization 강의를 본 후 공부를 목적으로 작성한 게시물입니다.
Weight Initialization
초기 weight의 설정은 크게 중요하지 않아 보이지만 실제로는 큰 영향을 미친다.
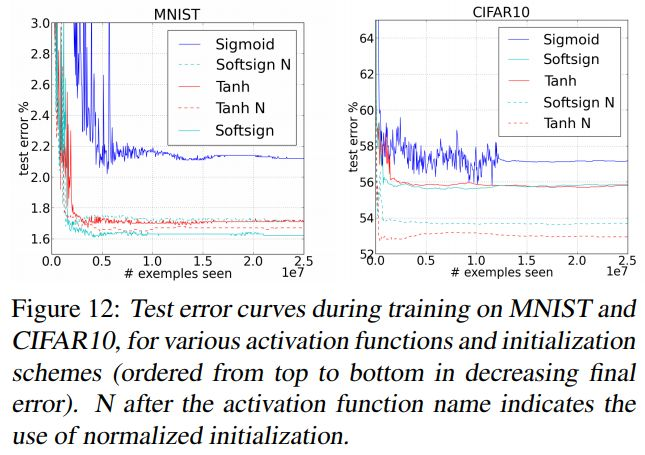
위 그래프에서도 볼 수 있듯이 적절한 초기화 기법으로 초기화를 해준 경우(N이 붙어있는 곡선) 실제로 오차가 줄어든 것을 확인할 수 있다.
DBN(Deep Belief Network)
RBM(Restricted Boltzmann Machine)
DBN을 알기 전에 먼저 RBM을 알고 가야 한다.
 레이어들의 전연결 구조이다. 일종의 encode(위쪽 방향으로 진행), decode(아래쪽 방향으로 진행)를 수행한다고 볼 수도 있다.
DBN
DBN은 RBM을 통해 적절한 weight를 찾아 초기화한다.
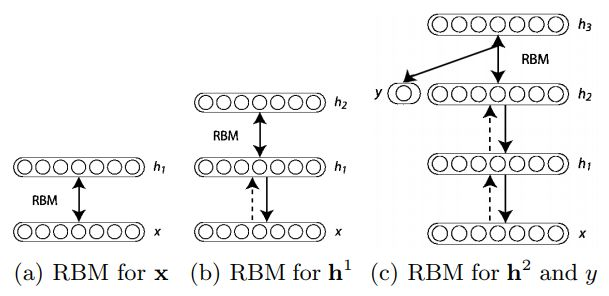
위와 같이 각 레이어마다 RBM을 구성하여 다음 레이어로 한 번 갔다가 다시 돌아와 봐서 잘 복원이 되는 weight를 찾아 그것으로 초기화하여 학습에 사용한다. 이전의 포스트에서 알아봤던 Stacking Autoencoder도 이 DBN의 한 종류이다.
하지만 요즘은 거의 사용하지 않는 방법이다.
Xavier / He Initialization
이 두가지 방법이 현재 많이 사용되는 방법인데, 이 방식들은 DBN과 같이 복잡한 학습들이 필요하지 않다는 것이다.
단순히 분포에 따라 아래 공식을 적용하여 in/out의 node 수를 통해 계산한 값을 이용하여 초기화한다.

1
2
3
4
5
6
def xavier_uniform_(tensor, gain=1):
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
std = gain * math.sqrt(2.0 / (fan_in + fan_out))
a = math.sqrt(3.0) * std # Calculate uniform bounds from standard deviation
with torch.no_grad():
return tensor.uniform_(-a, a)
실제 xavier의 구현을 보면 위와 같이 공식 그대로 계산하여 return해 주는 것을 볼 수 있다.
Train with Xavier
Xavier를 통해 앞서 학습해봤던 MLP를 학습하려면 다음 부분만 변경해 주면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# nn layers
linear1 = torch.nn.Linear(784, 256, bias=True)
linear2 = torch.nn.Linear(256, 256, bias=True)
linear3 = torch.nn.Linear(256, 10, bias=True)
relu = torch.nn.ReLU()
# xavier initialization
torch.nn.init.xavier_uniform_(linear1.weight) # not torch.nn.init.normal_()
torch.nn.init.xavier_uniform_(linear2.weight)
torch.nn.init.xavier_uniform_(linear3.weight)
'''output
Parameter containing:
tensor([[-0.0215, -0.0894, 0.0598, ..., 0.0200, 0.0203, 0.1212],
[ 0.0078, 0.1378, 0.0920, ..., 0.0975, 0.1458, -0.0302],
[ 0.1270, -0.1296, 0.1049, ..., 0.0124, 0.1173, -0.0901],
...,
[ 0.0661, -0.1025, 0.1437, ..., 0.0784, 0.0977, -0.0396],
[ 0.0430, -0.1274, -0.0134, ..., -0.0582, 0.1201, 0.1479],
[-0.1433, 0.0200, -0.0568, ..., 0.0787, 0.0428, -0.0036]],
requires_grad=True)
'''
torch.nn.init.normal_()대신 torch.nn.init.xavier_uniform_()을 사용하여 초기화를 진행한다.
Deep
더 깊은 네트워크도 마찬가지로 레이어마다 torch.nn.init.xavier_uniform_()을 사용해 주면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# nn layers
linear1 = torch.nn.Linear(784, 512, bias=True)
linear2 = torch.nn.Linear(512, 512, bias=True)
linear3 = torch.nn.Linear(512, 512, bias=True)
linear4 = torch.nn.Linear(512, 512, bias=True)
linear5 = torch.nn.Linear(512, 10, bias=True)
relu = torch.nn.ReLU()
# xavier initialization
torch.nn.init.xavier_uniform_(linear1.weight)
torch.nn.init.xavier_uniform_(linear2.weight)
torch.nn.init.xavier_uniform_(linear3.weight)
torch.nn.init.xavier_uniform_(linear4.weight)
torch.nn.init.xavier_uniform_(linear5.weight)
'''output
Parameter containing:
tensor([[-0.0565, 0.0423, -0.0155, ..., 0.1012, 0.0459, -0.0191],
[ 0.0772, 0.0452, -0.0638, ..., 0.0476, -0.0638, 0.0528],
[ 0.0311, -0.1023, -0.0701, ..., 0.0412, -0.1004, 0.0738],
...,
[ 0.0334, 0.0187, -0.1021, ..., 0.0280, -0.0583, -0.1018],
[-0.0506, -0.0939, -0.0467, ..., -0.0554, -0.0325, 0.0640],
[-0.0183, -0.0123, 0.1025, ..., -0.0214, 0.0220, -0.0741]],
requires_grad=True)
'''
{kind=link}