모두를 위한 딥러닝 2 - Lab9-1:ReLU
모두를 위한 딥러닝 Lab9-1: ReLU 강의를 본 후 공부를 목적으로 작성한 게시물입니다.
Problem of Sigmoid
시그모이드 함수의 문제는 backpropagation과정에서 발생한다. backpropagation을 수행할 때 activation의 미분값 곱해가면서 사용하게 되는데 이때 기울기가 소실되는 gradient vanishing문제가 발생한다. 다음 그림은 시그모이드 함수와 그 미분 함수의 그래프이다.
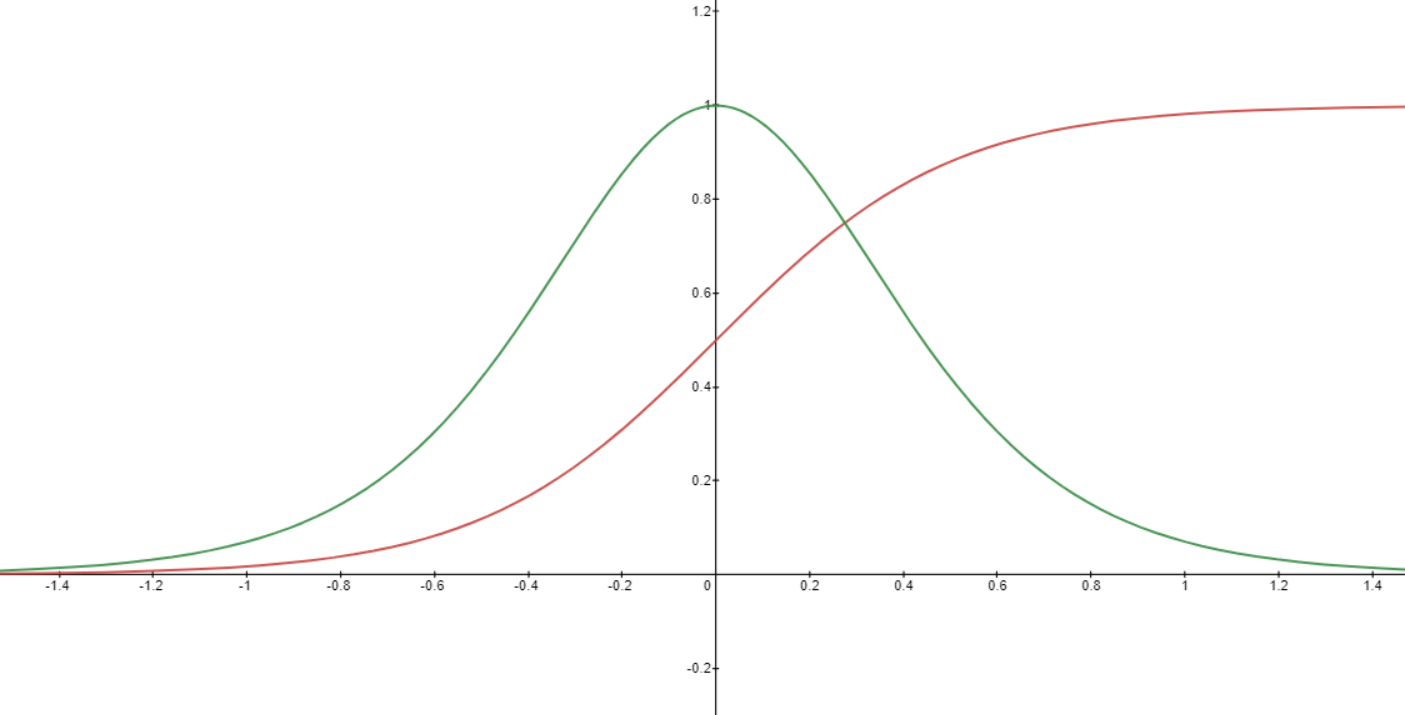
$x$ 값이 0에서 멀어질수록 미분값이 0에 수렴하는 것을 확인할 수 있다. 한두번의 곱으로 0이 되지는 않을지라도 여러번 반복하면서 수행하게 되면 곱이 여러번 중첩되어 0으로 수렴하게 될 것이다.
그렇게 되면 정상적인 학습이 불가능하다. 이런 시그모이드의 단점을 해결하기 위해 나온 것이 ReLU이다.
ReLU
ReLU의 식과 모습은 다음과 같이 간단히 주어진다.
\[f(x)=max(0,x)\]]
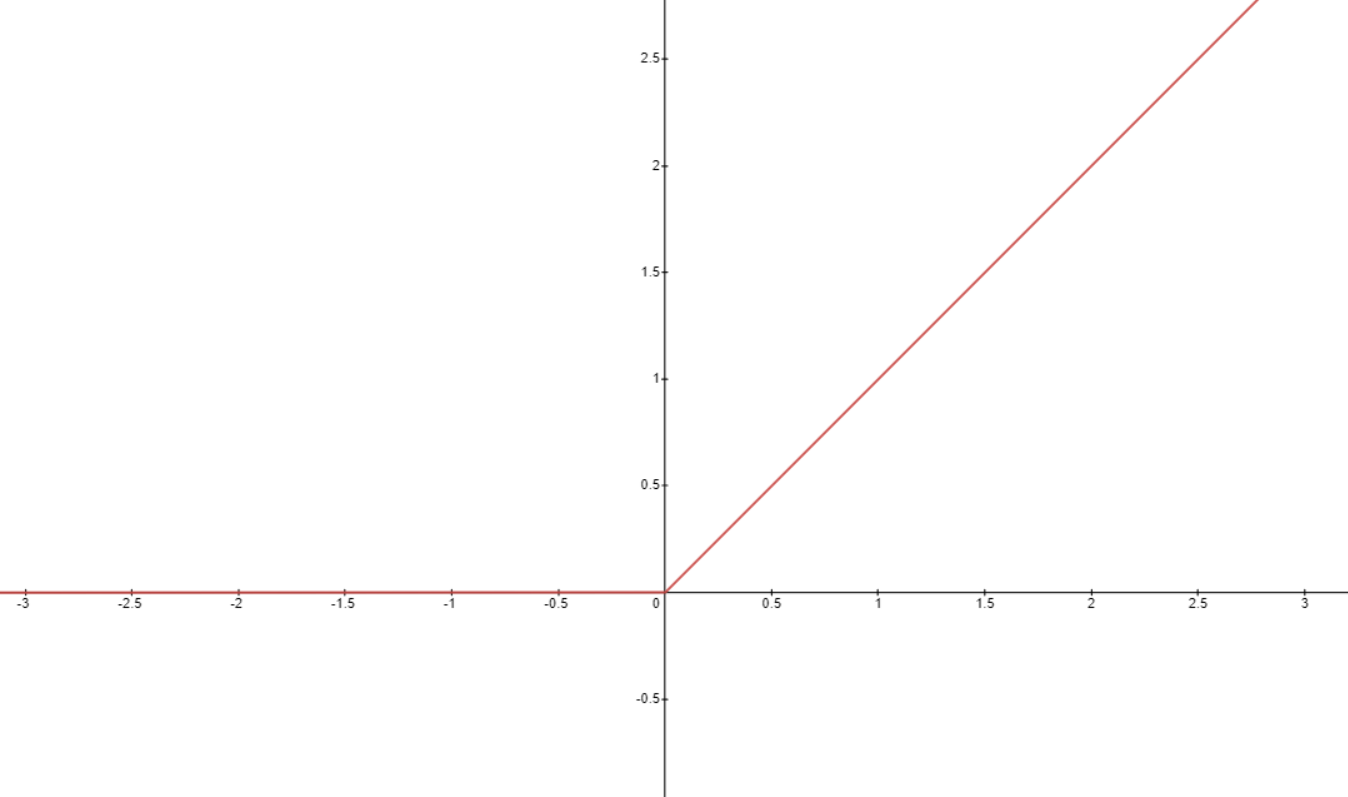
이렇게 activation을 구성할 경우 0 이상의 값들에 대해서는 미분값이 1이 나와 기울기 소실을 막을 수 있다.
PyTorch는 이런 activation들을 torch.nn.ReLU 등으로 불러 사용할 수 있으며 많이 사용하는 것들은 아래와 같다.
1
2
3
4
torch.nn.ReLU
torch.nn.LeakyReLU
torch.nn.Sigmoid
torch.nn.Tanh
Optimizer
이번 강의에서는 여러 optimizer에 대해서도 소개를 했는데, torch.optim으로 사용할 수 있는 optimizer로는 우리가 계속 사용한 SGD 말고도 다음과 같이 많이 존재한다.
1
2
3
4
5
6
7
8
9
10
torch.optim.SGD
torch.optim.Adadelta
torch.optim.Adagrad
torch.optim.Adam
torch.optim.SparseAdam
torch.optim.Adamax
torch.optim.ASGD
torch.optim.LBFGS
torch.optim.RMSprop
torch.optim.Rprop
optimizer에 대해서는 추후에 한번 자세히 공부해 보고 따로 포스팅 하려고 한다.
Train
Lab7-2에서 했던 mnist 학습을 adam optimizer로 한 번 학습해보고, 다중 레이어에 ReLU를 적용해서 또 한번 학습해 보겠다.
Adam
데이터나 모델을 정의하는 것은 모두 이전과 동일하기 때문에 달라진 부분에 초점을 맞춰 코드를 한 번 보도록 하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(linear.parameters(), lr=learning_rate) # Adam optimizer
total_batch = len(data_loader)
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
# reshape input image into [batch_size by 784]
# label is not one-hot encoded
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = linear(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning finished')
'''output
Epoch: 0001 cost = 4.848181248
Epoch: 0002 cost = 1.464641452
Epoch: 0003 cost = 0.977406502
Epoch: 0004 cost = 0.790303528
Epoch: 0005 cost = 0.686833322
Epoch: 0006 cost = 0.618483305
Epoch: 0007 cost = 0.568978667
Epoch: 0008 cost = 0.531290889
Epoch: 0009 cost = 0.501056492
Epoch: 0010 cost = 0.476258427
Epoch: 0011 cost = 0.455025405
Epoch: 0012 cost = 0.437031567
Epoch: 0013 cost = 0.421489984
Epoch: 0014 cost = 0.408599794
Epoch: 0015 cost = 0.396514893
Learning finished
'''
달라진 점은 optimizer를 정의할 때 torch.optim.Adam을 사용하였다는 것 뿐이다.
MLP with ReLU
1
2
3
4
5
6
7
8
9
10
11
12
13
# nn layers
linear1 = torch.nn.Linear(784, 256, bias=True)
linear2 = torch.nn.Linear(256, 256, bias=True)
linear3 = torch.nn.Linear(256, 10, bias=True)
relu = torch.nn.ReLU()
# Initialization
torch.nn.init.normal_(linear1.weight)
torch.nn.init.normal_(linear2.weight)
torch.nn.init.normal_(linear3.weight)
# model
model = torch.nn.Sequential(linear1, relu, linear2, relu, linear3).to(device)
여기서 달라진 것은 다중 레이어를 쌓고, 활성화 함수로 ReLU를 사용하여 모델을 구성했다는 것이다.
학습 결과는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
total_batch = len(data_loader)
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
# reshape input image into [batch_size by 784]
# label is not one-hot encoded
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning finished')
'''output
Epoch: 0001 cost = 129.325607300
Epoch: 0002 cost = 36.169139862
Epoch: 0003 cost = 23.025590897
Epoch: 0004 cost = 16.021036148
Epoch: 0005 cost = 11.609578133
Epoch: 0006 cost = 8.560424805
Epoch: 0007 cost = 6.369730949
Epoch: 0008 cost = 4.782918930
Epoch: 0009 cost = 3.604729652
Epoch: 0010 cost = 2.682321310
Epoch: 0011 cost = 2.086567640
Epoch: 0012 cost = 1.640438557
Epoch: 0013 cost = 1.297079921
Epoch: 0014 cost = 1.083126664
Epoch: 0015 cost = 0.751341939
Learning finished
'''