모두를 위한 딥러닝 2 - Lab11-5: Seq2Seq
모두를 위한 딥러닝 Lab11-5: Seq2Seq 강의를 본 후 공부를 목적으로 작성한 게시물입니다.
Seq2Seq Model
Seq2Seq model은 아래와 같은 구조를 가지고 있다.
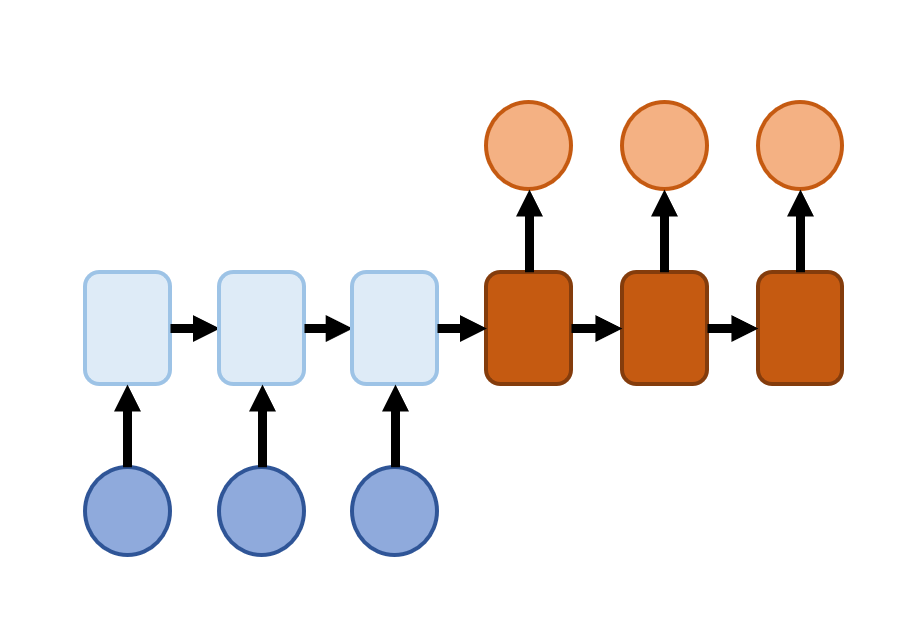
일종의 Encoder-Decoder 구조라고도 할 수 있는데 모든 입력을 다 받은 후에 출력을 생성하는 구조이다.
왼쪽(파란색)에서는 입력 받은 정보들을 순차적으로 학습하여 정보를 vector로 압축하는 역할을 하고, 오른쪽(주황색)에서는 압축한 정보를 전달받아 start flag(Start Of Sentence, SOS)와 함께 다음에 등장할 데이터를 예측하면서 순차적으로 output을 내고 마지막에는 end flag(Etart Of Sentence, EOS)를 출력하여 데이터의 끝이라는 것을 알려준다.
간단한 문장에 대한 대답을 에로 들면 다음과 같다. 내부 layer는 LSTM나 GRU를 사용한다.
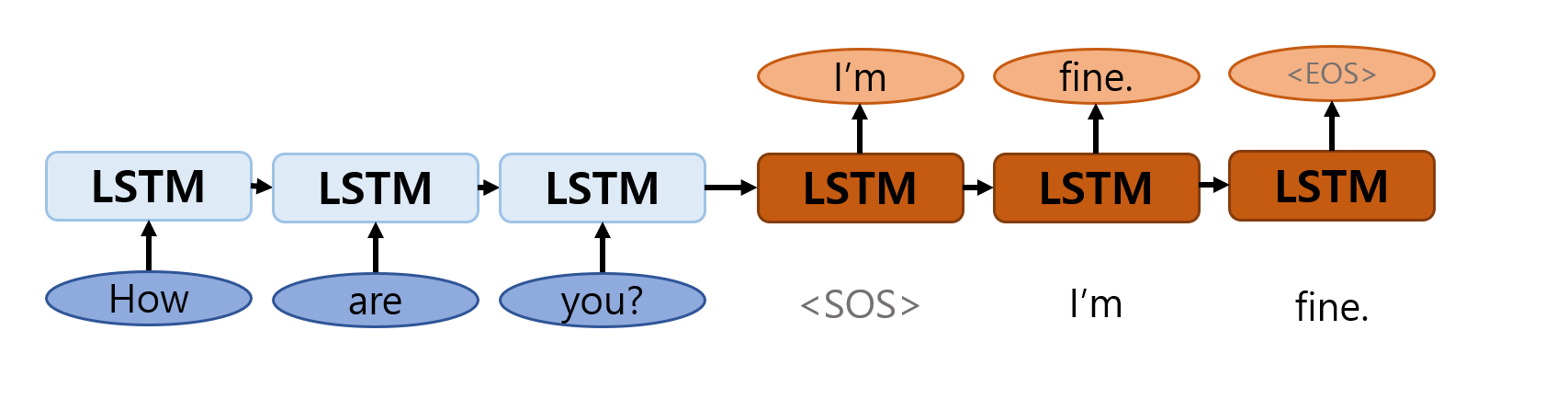
이를 사용하는 에로는 chatbot이 있을 수 있는데 chatbot은 사용자의 입력(문장)을 다 듣기 전에 답변을 만들 경우 실제 문장과 상관없는 답변을 생성할 수도 있다. 이런 경우 처럼 input sequence의 전체를 다 확인하고 출력이 있어야 하는 경우에 Seq2Seq model을 사용하게 된다.
with Code
간단한 번역을 할 수 있는 model을 학습시키는 실습이다.
Imports
1
2
3
4
5
6
7
import random
import torch
import torch.nn as nn
from torch import optim
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Data
아래 data를 처리하여 사용할 것이다. data는 같은 뜻의 영어와 한국어로 구성되어 있고 각 영어와 하눆어는 tab으로 구분되어 있다.
1
2
3
4
raw = ["I feel hungry. 나는 배가 고프다.",
"Pytorch is very easy. 파이토치는 매우 쉽다.",
"Pytorch is a framework for deep learning. 파이토치는 딥러닝을 위한 프레임워크이다.",
"Pytorch is very clear to use. 파이토치는 사용하기 매우 직관적이다."]
data를 전처리하는 함수를 만들어 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# fix token for "start of sentence" and "end of sentence"
SOS_token = 0
EOS_token = 1
class Vocab:
def __init__(self):
self.vocab2index = {"<SOS>": SOS_token, "<EOS>": EOS_token}
self.index2vocab = {SOS_token: "<SOS>", EOS_token: "<EOS>"}
self.vocab_count = {}
self.n_vocab = len(self.vocab2index)
def add_vocab(self, sentence):
for word in sentence.split(" "):
if word not in self.vocab2index:
self.vocab2index[word] = self.n_vocab
self.vocab_count[word] = 1
self.index2vocab[self.n_vocab] = word
self.n_vocab += 1
else:
self.vocab_count[word] += 1
def filter_pair(pair, source_max_length, target_max_length):
return len(pair[0].split(" ")) < source_max_length and len(pair[1].split(" ")) < target_max_length
def preprocess(corpus, source_max_length, target_max_length):
print("reading corpus...")
pairs = []
for line in corpus:
pairs.append([s for s in line.strip().lower().split("\t")])
print("Read {} sentence pairs".format(len(pairs)))
pairs = [pair for pair in pairs if filter_pair(pair, source_max_length, target_max_length)]
print("Trimmed to {} sentence pairs".format(len(pairs)))
source_vocab = Vocab()
target_vocab = Vocab()
print("Counting words...")
for pair in pairs:
source_vocab.add_vocab(pair[0])
target_vocab.add_vocab(pair[1])
print("source vocab size =", source_vocab.n_vocab)
print("target vocab size =", target_vocab.n_vocab)
return pairs, source_vocab, target_vocab
먼저 \t(tab)으로 나눠서 pairs에 넣어주고 filter_pair로 각 문장의 단어 개수가 source_max_length와 target_max_length를 넘지 않는 경우만 필터링한다. 정제된 데이터들을 따로 정의한 Vocab instance를 통해 단어의 종류와 그 개수로 이루어진 dictionary data로 만들어준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
SOURCE_MAX_LENGTH = 10
TARGET_MAX_LENGTH = 12
load_pairs, load_source_vocab, load_target_vocab = preprocess(raw, SOURCE_MAX_LENGTH, TARGET_MAX_LENGTH)
print(random.choice(load_pairs))
'''output
reading corpus...
Read 4 sentence pairs
Trimmed to 4 sentence pairs
Counting words...
source vocab size = 17
target vocab size = 13
['pytorch is very clear to use.', '파이토치는 사용하기 매우 직관적이다.']
'''
4개의 문장이 모두 잘 변환이 되었고 무작위로 하나를 골라 출력해보면 위와 같이 쌍이 잘 나오는 것을 확인할 수 있다.
Model
Model은 앞에서 언급한 것과 같이 encoder와 decoder로 이루어져 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, x, hidden):
x = self.embedding(x).view(1, 1, -1)
x, hidden = self.gru(x, hidden)
return x, hidden
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, x, hidden):
x = self.embedding(x).view(1, 1, -1)
x, hidden = self.gru(x, hidden)
x = self.softmax(self.out(x[0]))
return x, hidden
이번 model의 내부는 GRU로 구성한다. 다른 것들은 크게 다른 점은 없지만 조금 다른 것은 embedding 부분이다. source의 oen-hot vector는 단어 개수 만큼 input size가 커지게 되는데 이때의 차원은 그냥 학습하기에 너무 클 수 있다. 그래서 nn.Embedding을 통해 차원을 줄여 밀집되게 바꿔 사용할 수 있다.
Decoder에서는 model을 통해 만든 것들을 softmax를 통해 단어들이 나올 확률로 내보낸다.
Train
학습하는 코드는 조금 길기 때문에 잘라서 보자.
먼저 trian 안에서 사용할 tensorize 함수다.
1
2
3
4
5
# convert sentence to the index tensor with vocab
def tensorize(vocab, sentence):
indexes = [vocab.vocab2index[word] for word in sentence.split(" ")]
indexes.append(vocab.vocab2index["<EOS>"])
return torch.Tensor(indexes).long().to(device).view(-1, 1)
전처리 할 때 Vocab에 저장했던 문장들을 학습할 수 있도록 Tensor로 바꿔주는 함수이다.
다음은 train의 앞부분이다. 무작위로 n_iter만큼 뽑아서 batch data를 만들어주고, 앞서 정의한 tensorize를 아용하여 data들을 모두 Tensor로 바꿔주고 encoder/decoder의 optimizer와 loss를 정의해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# training seq2seq
def train(pairs, source_vocab, target_vocab, encoder, decoder, n_iter, print_every=1000, learning_rate=0.01):
loss_total = 0
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
training_batch = [random.choice(pairs) for _ in range(n_iter)]
training_source = [tensorize(source_vocab, pair[0]) for pair in training_batch]
training_target = [tensorize(target_vocab, pair[1]) for pair in training_batch]
criterion = nn.NLLLoss()
...
위에서 처리하고 정의한 것들을 기반으로 encoder를 학습하는 부분이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# training seq2seq
def train(pairs, source_vocab, target_vocab, encoder, decoder, n_iter, print_every=1000, learning_rate=0.01):
...
for i in range(1, n_iter + 1):
source_tensor = training_source[i - 1]
target_tensor = training_target[i - 1]
encoder_hidden = torch.zeros([1, 1, encoder.hidden_size]).to(device)
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
source_length = source_tensor.size(0)
target_length = target_tensor.size(0)
loss = 0
for enc_input in range(source_length):
_, encoder_hidden = encoder(source_tensor[enc_input], encoder_hidden)
...
문장을 하나씩 가져와서 문장의 단어를 하나씩 순차적으로 넣어가면서 encoder의 출력을 만든다. 이때 각 학습의 맨 처음 encoder_hidden은 0으로 채운 Tensor를 사용한다.
다음은 decoder의 학습이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# training seq2seq
def train(pairs, source_vocab, target_vocab, encoder, decoder, n_iter, print_every=1000, learning_rate=0.01):
...
for i in range(1, n_iter + 1):
...
decoder_input = torch.Tensor([[SOS_token]]).long().to(device)
decoder_hidden = encoder_hidden # connect encoder output to decoder input
for di in range(target_length):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # teacher forcing
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
loss_iter = loss.item() / target_length
loss_total += loss_iter
if i % print_every == 0:
loss_avg = loss_total / print_every
loss_total = 0
print("[{} - {}%] loss = {:05.4f}".format(i, i / n_iter * 100, loss_avg))
decoder의 첫 input은 SOS로, hidden state는 encoder의 최종 hidden state로 넣어준다. for문을 동면서 decoder를 통과시키는 부분을 보면 decoder에서 나온 output을 다음 input으로 사용하는 것이 아니라 실제 label을 다음 cell에 넣어주는 것을 볼 수 있다. 이건 Teacher Forcing이라는 방법으로 이전 cell의 output을 사용하는 것보다 학습이 빠르지만 불안정하다는 특징을 가지고 있다.
이전까지 진행했던 과정들을 바탕으로 step을 통해 학습을 진행하고 n_iter만큼 반복한다.
1
2
3
4
5
6
7
8
9
train(load_pairs, load_source_vocab, load_target_vocab, enc, dec, 5000, print_every=1000)
'''output
[1000 - 20.0%] loss = 0.0285
[2000 - 40.0%] loss = 0.0168
[3000 - 60.0%] loss = 0.0119
[4000 - 80.0%] loss = 0.0091
[5000 - 100.0%] loss = 0.0074
'''
실제로 학습하면서 확인한 결과 loss가 잘 감소하였다.
Evaluate
마지막으로 평가를 위한 함수로, 실제 pair를 출력하고 그에 대한 예측도 함께 출력하여 잘 학습되었는지 확인할 수 있는 함수이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def evaluate(pairs, source_vocab, target_vocab, encoder, decoder, target_max_length):
for pair in pairs:
print(">", pair[0])
print("=", pair[1])
source_tensor = tensorize(source_vocab, pair[0])
source_length = source_tensor.size()[0]
encoder_hidden = torch.zeros([1, 1, encoder.hidden_size]).to(device)
for ei in range(source_length):
_, encoder_hidden = encoder(source_tensor[ei], encoder_hidden)
decoder_input = torch.Tensor([[SOS_token]]).long().to(device) # 수정해야 작동
decoder_hidden = encoder_hidden
decoded_words = []
for di in range(target_max_length):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
_, top_index = decoder_output.data.topk(1) # 1개의 가장 큰 요소를 반환
if top_index.item() == EOS_token:
decoded_words.append("<EOS>")
break
else:
decoded_words.append(target_vocab.index2vocab[top_index.item()])
decoder_input = top_index.squeeze().detach()
predict_words = decoded_words
predict_sentence = " ".join(predict_words)
print("<", predict_sentence)
print("")
data를 tensor로 만들어주고 학습했던 encoder와 decoder를 통과시켜 model이 에측한 문장을 출력한다. 이때 decoder의 실제 출력은 softmax를 통해 나온 확률들이기 때문에 topk(1)로 가장 큰 값의 index를 받아 Vocab의 단어로 바꿔준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
evaluate(load_pairs, load_source_vocab, load_target_vocab, enc, dec, TARGET_MAX_LENGTH)
'''output
> i feel hungry.
= 나는 배가 고프다.
< 나는 배가 고프다. <EOS>
> pytorch is very easy.
= 파이토치는 매우 쉽다.
< 파이토치는 매우 쉽다. <EOS>
> pytorch is a framework for deep learning.
= 파이토치는 딥러닝을 위한 프레임워크이다.
< 파이토치는 딥러닝을 위한 프레임워크이다. <EOS>
> pytorch is very clear to use.
= 파이토치는 사용하기 매우 직관적이다.
< 파이토치는 사용하기 매우 직관적이다. <EOS>
'''
출력 결과 기존의 문장들에 대해 학습을 잘 한 것을 확인할 수 있다.