모두를 위한 딥러닝 2 - Lab11-0: RNN intro
모두를 위한 딥러닝 Lab11-0: RNN intro 강의를 본 후 공부를 목적으로 작성한 게시물입니다.
RNN(Recurrent Neural Network)
RNN은 sequential data를 잘 학습하기 위해 고안된 모델이다. Sequential data란 단어, 문장이나 시게열 데이터와 같이 데이터의 순서도 데이터의 일부인 데이터들을 말한다. 이런 데이터는 이전 순서의 데이터들을 생각하여 학습을 하는 것이 더효과적일 것이다. 이렇게 학습하기 위해 RNN은 다음과 같은 구조로 구성되어 있다.
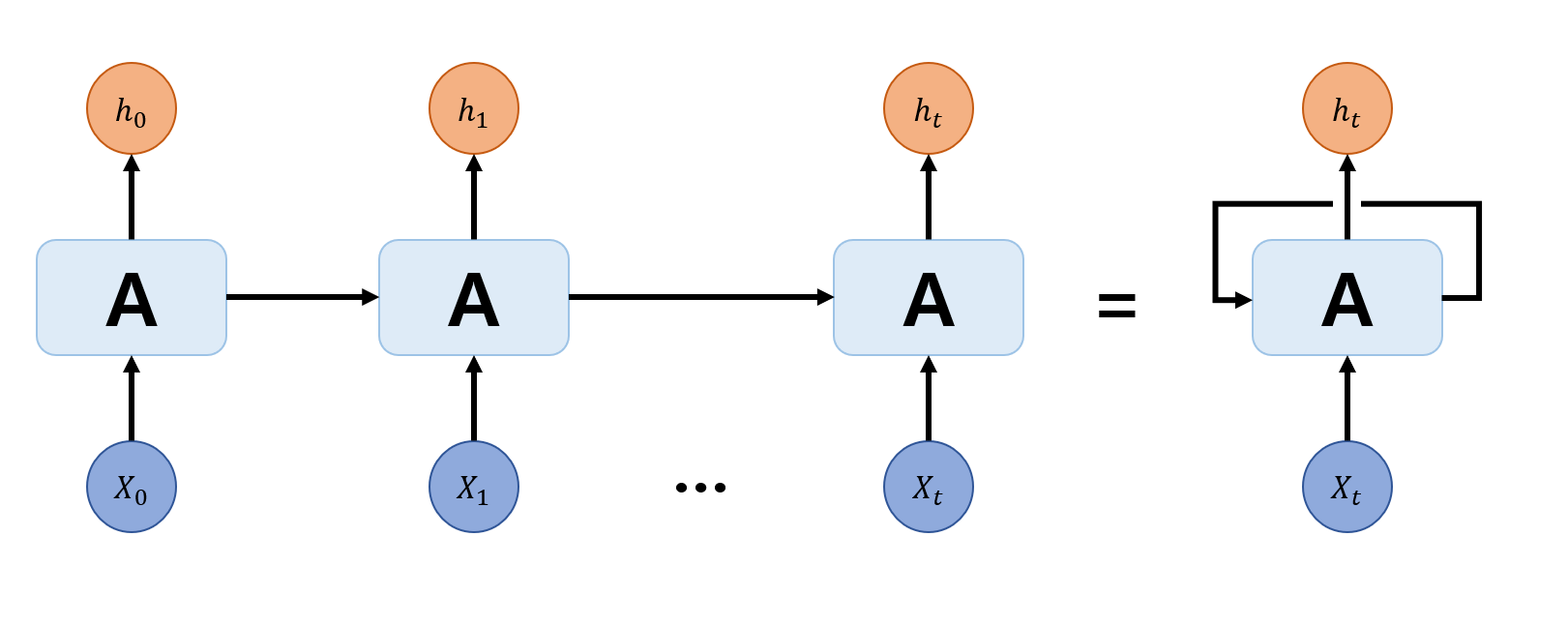
한 모델로 계속 학습하지만 이전의 output이 다음의 input과 함께 들어가는 구조이다. 이렇게 output을 다음 input으로 보낼 때 이 값을 hidden state라고 하며, 이런 식으로 모델을 구성하면 과거의 데이터를 반영하여 학습할 수 있게 된다.
이때 RNN 내부의 actiavtion은 tanh나 sigmoid function을 사용한다. 지금까지 봐왔던 network들은 기울기 소실 문제 때문에 ReLU를 사용해야 성능이 더 좋아진다고 했던 것 같은데 RNN의 내부에서는 왜 사용하지 않는 걸까. 그 이유는 RNN의 구조 때문인데, RNN은 같은 layer를 여러번 반복하여 학습하는 구조를 가진다. 이때 ReLU와 같은 activation을 사용하면 1보다 큰 수가 반복하여 곱해지기 때문에 기울기 폭발이 발생할 가능성이 매우 높다. 그래서 RNN의 내부에서 만큼은 절대값이 1을 넘지 않은 tanh나 sigmoid를 사용하는 것이다.
Acivation을 표현하여 조금 더 자세히 모델을 나타내면 다음과 같은 구조를 확인할 수 있다.
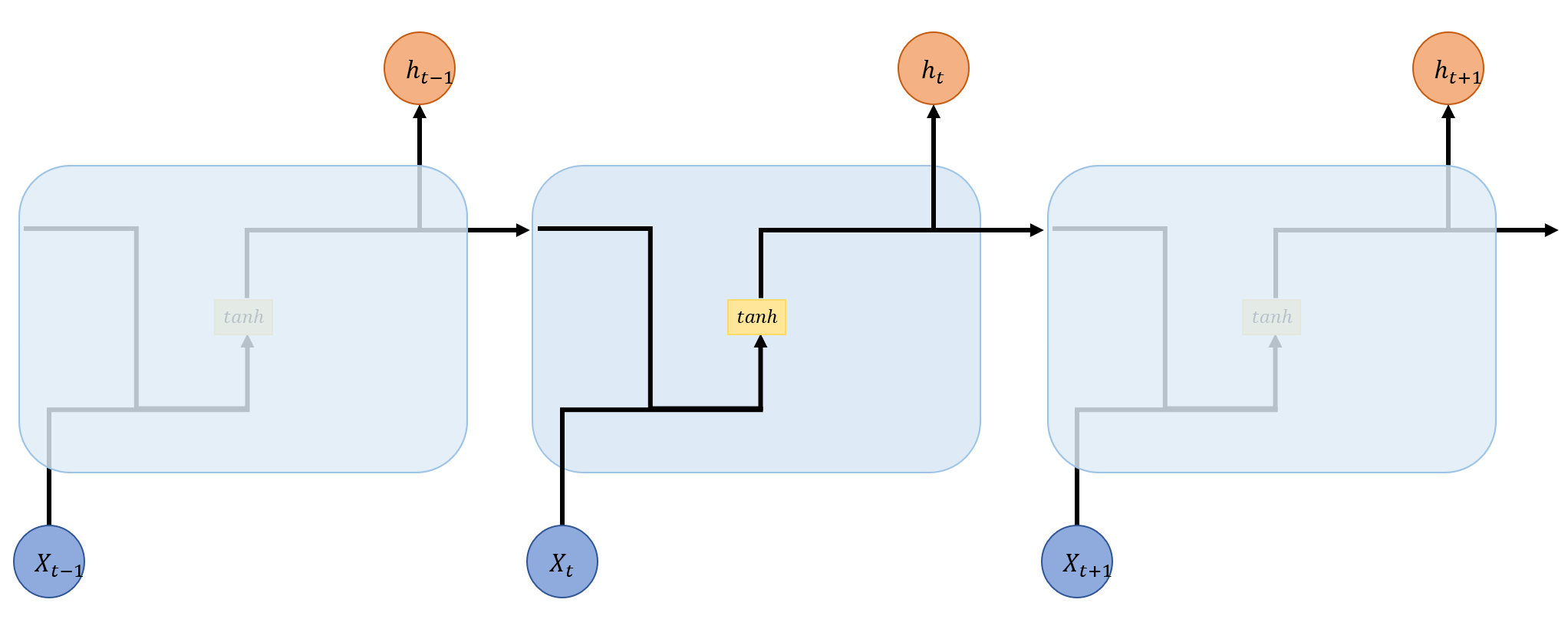
일반화하여 수식으로 나타내면 다음과 같고
\[h_t=f(h_{t-1}, x_t)\]
activation과 weight를 명시하여 표현하면 다음과 같다.
\[h_t=tanh(W_h h_{t-1}, W_x x_t)\]
Usages of RNN
이런 RNN의 구조를 응용하여 다음과 같은 구조들로 사용할 수 있다.
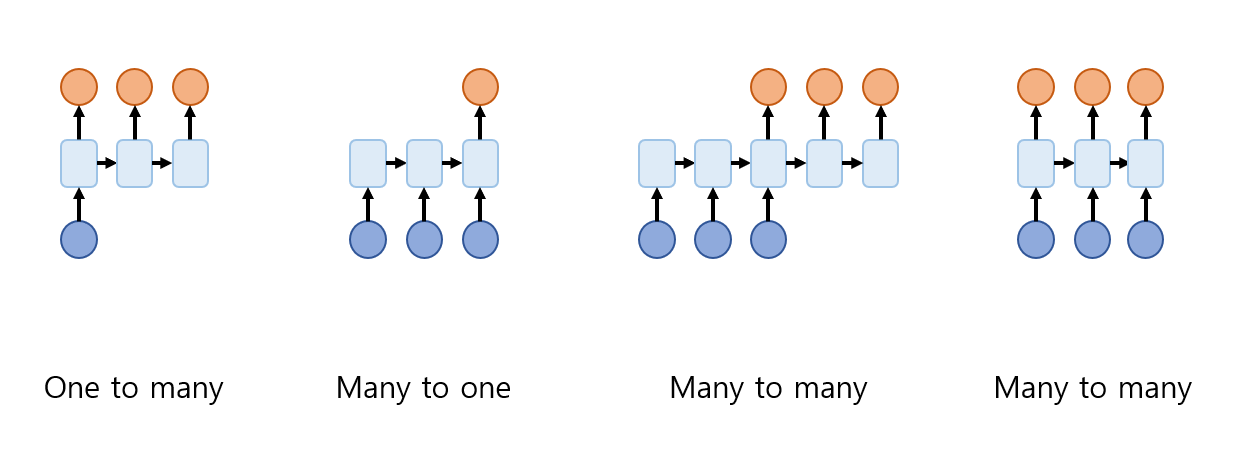
- one to many
- 하나의 입력을 받아 여러 출력을 내는 구조이다. 하나의 이미지를 받아 그에 대한 설명을 문장(여러개의 단어)으로 출력하는 것을 에로 들 수 있다.
- many to one
- 여러 입력을 받아 하나의 출럭을 내는 구조이다. 문장을 입력받아 그 문장이 나타내는 감정의 label을 출력하는 것을 예로 들 수 있다.
- many to many
- 2가지의 구조가 있는 것을 볼 수 있다.
- 입력이 다 끝나는 지점부터 여러 출력을 내는 구조로, 문장을 입력받아 번역하는 모델을 예로 들 수 있다. 이 경우 문장의 중간에 번역을 진행하면 다 끝나고 나서 문장의 의미가 달라질 수 있기 때문에 먼저 입력 문장을 다 듣고 번역을 진행하게 된다.
- 입력 하나하나를 받으면서 그때마다 모델의 출력을 내는 구조이다. 영상을 처리할 때 frame 단위의 이미지로 나눠 입력을 받은 후 각 frame을 입력 받을 때마다 처리하는 것을 예로 들 수 있다.