[BOJ]ACM Craft - 1005 (G3)
| 시간 제한 | 메모리 제한 |
|---|---|
| 1 초 | 512 MB |
문제
서기 2012년! 드디어 2년간 수많은 국민들을 기다리게 한 게임 ACM Craft (Association of Construction Manager Craft)가 발매되었다.
이 게임은 지금까지 나온 게임들과는 다르게 ACM크래프트는 다이나믹한 게임 진행을 위해 건물을 짓는 순서가 정해져 있지 않다. 즉, 첫 번째 게임과 두 번째 게임이 건물을 짓는 순서가 다를 수도 있다. 매 게임시작 시 건물을 짓는 순서가 주어진다. 또한 모든 건물은 각각 건설을 시작하여 완성이 될 때까지 Delay가 존재한다.

위의 예시를 보자.
이번 게임에서는 다음과 같이 건설 순서 규칙이 주어졌다. 1번 건물의 건설이 완료된다면 2번과 3번의 건설을 시작할수 있다. (동시에 진행이 가능하다) 그리고 4번 건물을 짓기 위해서는 2번과 3번 건물이 모두 건설 완료되어야지만 4번건물의 건설을 시작할수 있다.
따라서 4번건물의 건설을 완료하기 위해서는 우선 처음 1번 건물을 건설하는데 10초가 소요된다. 그리고 2번 건물과 3번 건물을 동시에 건설하기 시작하면 2번은 1초뒤에 건설이 완료되지만 아직 3번 건물이 완료되지 않았으므로 4번 건물을 건설할 수 없다. 3번 건물이 완성되고 나면 그때 4번 건물을 지을수 있으므로 4번 건물이 완성되기까지는 총 120초가 소요된다.
프로게이머 최백준은 애인과의 데이트 비용을 마련하기 위해 서강대학교배 ACM크래프트 대회에 참가했다! 최백준은 화려한 컨트롤 실력을 가지고 있기 때문에 모든 경기에서 특정 건물만 짓는다면 무조건 게임에서 이길 수 있다. 그러나 매 게임마다 특정건물을 짓기 위한 순서가 달라지므로 최백준은 좌절하고 있었다. 백준이를 위해 특정건물을 가장 빨리 지을 때까지 걸리는 최소시간을 알아내는 프로그램을 작성해주자.
입력
첫째 줄에는 테스트케이스의 개수 T가 주어진다. 각 테스트 케이스는 다음과 같이 주어진다. 첫째 줄에 건물의 개수 N과 건물간의 건설순서 규칙의 총 개수 K이 주어진다. (건물의 번호는 1번부터 N번까지 존재한다)
둘째 줄에는 각 건물당 건설에 걸리는 시간 D1, D2, …, DN이 공백을 사이로 주어진다. 셋째 줄부터 K+2줄까지 건설순서 X Y가 주어진다. (이는 건물 X를 지은 다음에 건물 Y를 짓는 것이 가능하다는 의미이다)
마지막 줄에는 백준이가 승리하기 위해 건설해야 할 건물의 번호 W가 주어진다.
출력
건물 W를 건설완료 하는데 드는 최소 시간을 출력한다. 편의상 건물을 짓는 명령을 내리는 데는 시간이 소요되지 않는다고 가정한다.
건설순서는 모든 건물이 건설 가능하도록 주어진다.
풀이
첫 접근
처음 문제를 봤을 때는 그래프 구조 문제이고, BFS를 기반으로 접근해야겠다고 생각했다. DFS로 접근하면 목표한 건물이 없는 길이 너무 깊다면 시간 복잡도가 너무 증가할 것이라고 생각했다. 또한 한 건물로 가는 길이 여러 개이며, 목표 건물에 도달하는 길을 모두 탐색했으면 더 깊게 탐색할 필요가 없기 때문에 DFS는 매우 불리할 것이라 생각했다.
문제에서는 어떤 건물로 건축을 시작해야 하는지 정확히 명시하지 않고 있다. 그래서 코드 내에서 이를 해결해 주어야 한다. 어떤 건물이 처음으로 지어질 수 있다는 것은 그 건물을 짓기 전에 다른 건물들을 지을 필요가 없다는 뜻이며 이는 건설 순서를 입력 받을 때 Y로 입력되지 않았던 값이다. Y로 한 번이라도 입력된 값은 적어도 하나 이상의 건물을 지어야 그 건물을 지을 수 있다는 것이기 때문이다. 처음 시작하는 건물들은 다음과 같이 찾아낼 수 있다.
1
2
3
4
5
6
7
8
9
...
first_val = list(range(1, n + 1))
for i in range(k):
x, y = map(int, input().split())
xy_dict[x].append(y)
...
try: first_val.remove(y)
except: pass
...
모든 건물 번호가 들어가 있는 배열에서 Y로 입력된 값들만 삭제한다. 이후 탐색하면서 time딕셔너리에 건물 번호 : 짓는데 걸리는 시간을 key : vlaue로 저장해준다. 시간을 저장할 때는 여러 건물을 동시에 지을 수 있기 때문에 탐색하면서 계산한 시간들 중에 가장 큰 것만 저장하면 된다. 코드는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
...
for k in keys:
tmp = []
for v in xy_dict[k]:
...
if v not in times:
times[v] = times[k] + d_list[v - 1]
else:
times[v] = max(times[k] + d_list[v - 1], times[v])
...
탐색하면서 나온 건물들(v)을 다시 queue에 넣어주면서 BFS를 진행한다.
다만, 목표 건물이 Y로 한 번도 등장하지 않았다면 필요 건물이 없다는 것이므로 바로 목표 건물의 건축 시간을 출력한다.
1
2
3
4
5
...
if counts[target] != 0:
print(bfs(xy_dict, d_list, first_val, target, counts[target]))
else:
print(d_list[target - 1])
하지만 이렇게 처리를 하고 BFS 기반으로만 풀어나가면 모든 경우들을 처리하기 쉽지 않다. 다음 예제를 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1
5 10
100000 99999 99997 99994 99990
4 5
3 5
3 4
2 5
2 4
2 3
1 5
1 4
1 3
1 2
4
입력되는 순서를 변경하지 않고 단순하게 탐색을 진행하면 2, 3 번 건물의 탐색이 끝나기 전에 4번의 탐색이 완료되어 버려 오답이 출력 된다.
첫 접근 전체 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
import sys
from collections import defaultdict
input = sys.stdin.readline
def bfs(xy_dict, d_list, first_val, target, target_num):
first_idx = 0
q = []
times = {}
times[first_val[0]] = d_list[first_val[0] - 1]
keys = [first_val[0]]
while True:
if q:
keys = q.pop(0)
for k in keys:
tmp = []
for v in xy_dict[k]:
if target == v: target_num -= 1
tmp.append(v)
if v not in times:
times[v] = times[k] + d_list[v - 1]
else:
times[v] = max(times[k] + d_list[v - 1], times[v])
q.append(tmp)
if target_num == 0:
return times[target]
if not q:
first_idx += 1
next = first_val[first_idx]
times[next] = d_list[next - 1]
keys = [next]
t = int(input())
for _ in range(t):
n, k = map(int, input().split())
xy_dict = defaultdict(list)
d_list = list(map(int, input().split()))
counts = {i:0 for i in range(1, n + 1)}
first_val = list(range(1, n + 1))
for i in range(k):
x, y = map(int, input().split())
xy_dict[x].append(y)
counts[y] += 1
try: first_val.remove(y)
except: pass
target = int(input())
for x in xy_dict:
xy_dict[x].sort(key=lambda x: counts[x])
if counts[target] != 0:
print(bfs(xy_dict, d_list, first_val, target, counts[target]))
else:
print(d_list[target - 1])
다른 접근
다른 방식의 접근이 필요하다 생각하여 순서를 정하는 주요한 요인이 무엇일까 생각해 봤다. 위 방식에서 문제가 됐던 것은 먼저 지어져야 할 건물의 탐색이 끝나기 전에 다음 단계의 건물을 탐색하기 시작한다는 것이다. 이때 건물들의 순서는 해당 건물의 짓기 위해 먼저 지어야 하는 건물들의 개수로 정의할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1
5 10
100000 99999 99997 99994 99990
4 5
3 5
3 4
2 5
2 4
2 3
1 5
1 4
1 3
1 2
4
위에서 봤던 예제를 다시 보면서 생각해보자.
각 건물들의 짓기 위해 필요한 건물들의 개수를 나타내보면 다음과 같다.
| 건물 번호 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 필요 건물 | 0 | 1 | 2 | 3 | 4 |
필요 건물이 많을수록 뒤에 탐색하면 위에서 말했던 문제를 해결할 수 있다.
탐색을 할 건물은 항상 필요 건물이 0인 것들로만 구성할 것이다. 이를 어떻게 하는지 탐색 과정을 세세하게 확인해 보자. 현재 건물들의 관계를 그래프로 나타내면 다음과 같다.
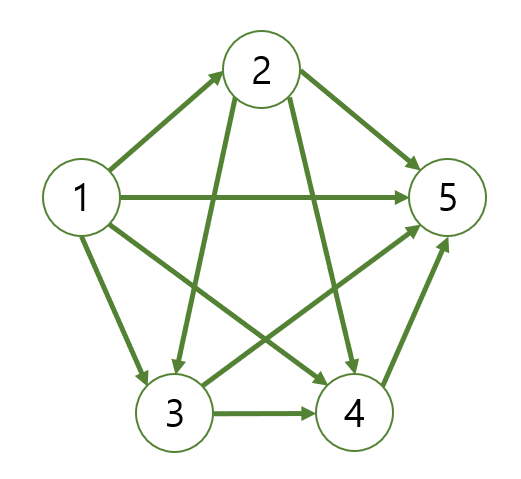
| 건물 번호 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 필요 건물 | 0 | 1 | 2 | 3 | 4 |
queue: 1
탐색 완료:
처음에는 필요 건물이 0인 경우가 1 밖에 없으므로 queue에 1을 넣어준다.
| 건물 번호 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 필요 건물 | 0 | 0 | 1 | 2 | 3 |
queue: 2
탐색 완료: 1
1은 2, 3, 4, 5와 연결되어 있으므로 1의 탐색이 끝나면(다 지어지면) 2, 3, 4, 5의 필요 건물을 하나씩 줄일 수 있다. 필요 건물을 줄인 후에 탐색이 가능한 건물은 2번이다(필요 건물이 0이 되었기 때문). 이런 방식으로 계속 탐색한다.
| 건물 번호 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 필요 건물 | 0 | 0 | 0 | 1 | 2 |
queue: 3
탐색 완료: 1, 2
| 건물 번호 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 필요 건물 | 0 | 0 | 0 | 0 | 1 |
queue: 4
탐색 완료: 1, 2, 3
이렇게 목표 건물이 4번이 queue에 들어와 탐색을 마치면 4번 건물을 지었다는 것이므로 탐색을 멈추고 저장해두었던 시간을 출력하면 된다.
이 문제의 입력으로 주어지는 건물들로 만들어진 그래프는 항상 방향성을 가지며, 항상 모든 건물이 건축 가능하도록 주어진다고 했기 때문에 acyclic이다. 즉 이 문제의 그래프는 DAG(Directed Acyclic Graph)이다. DAG에서 어떤 노드로 들어오는 간선의 개수를 indegree라고 하는데 이 indegree의 개수에 따라 정렬하는 것을 위상 정렬(topologicla sort)이라고 한다.
따라서 우리가 위에서 필요 건물(indegree)에 따라 정렬하여 시간을 계산한 것은 위상 정렬을 이용한 알고리즘인 것이다.
최종 전체 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import sys
from collections import defaultdict
input = sys.stdin.readline
def topological_sort(xy_dict, d_list, first_val, counts, target):
times = {val:d_list[val - 1] for val in first_val}
q = first_val
while q:
cur = q.pop(0)
if cur == target: return times[target]
for next in xy_dict[cur]:
if next not in times:
times[next] = times[cur] + d_list[next - 1]
else:
times[next] = max(times[cur] + d_list[next - 1], times[next])
counts[next] -= 1
tmp = list(counts.keys())[:]
for i in tmp:
if counts[i] == 0:
q.append(i)
del counts[i]
t = int(input())
for _ in range(t):
n, k = map(int, input().split())
xy_dict = defaultdict(list)
d_list = list(map(int, input().split()))
counts = defaultdict(int)
first_val = list(range(1, n + 1))
for i in range(k):
x, y = map(int, input().split())
xy_dict[x].append(y)
counts[y] += 1
try: first_val.remove(y)
except: pass
target = int(input())
if target in counts:
print(topological_sort(xy_dict, d_list, first_val, counts, target))
else:
print(d_list[target - 1])